Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /home/platne/serwer318421/public_html/zeszyt.jedlikowski.com/wp-content/plugins/latex/latex.php on line 47
Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /home/platne/serwer318421/public_html/zeszyt.jedlikowski.com/wp-content/plugins/latex/latex.php on line 49
Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /home/platne/serwer318421/public_html/zeszyt.jedlikowski.com/wp-content/plugins/latex/latex.php on line 47
Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /home/platne/serwer318421/public_html/zeszyt.jedlikowski.com/wp-content/plugins/latex/latex.php on line 49
Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /home/platne/serwer318421/public_html/zeszyt.jedlikowski.com/wp-content/plugins/latex/latex.php on line 47
Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /home/platne/serwer318421/public_html/zeszyt.jedlikowski.com/wp-content/plugins/latex/latex.php on line 49
Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /home/platne/serwer318421/public_html/zeszyt.jedlikowski.com/wp-content/plugins/latex/latex.php on line 47
Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /home/platne/serwer318421/public_html/zeszyt.jedlikowski.com/wp-content/plugins/latex/latex.php on line 49
Model bazy danych to ogólny sposób logicznej reprezentacji danych w bazie danych. Dane są fizycznie zapisane w rekordach, plikach, natomiast aplikacja widzi je jako tabele powiązane związkami klucz obcy-klucz główny (w modelu relacyjnym), jako hierarchie plików rekordów (w modelu hierarchicznym), jako sieci plików rekordów (w modelu sieciowym), jako zbiory obiektów powiązanych przez wskaźniki (w modelu obiektowym).
Poziom abstrakcji - baza danych jest udostępniona na trzech różnych poziomach abstrakcji: logicznym (operacje na tabelach), fizycznym (operacje na plikach rekordów) i zewnętrznym (operacje na perspektywach użytkowników). Na każdym z poziomów zapewniona jest pełna obsługa operacji, bez przechodzenia w inny poziom.
Niezależność danych - zmiany zachodzące na niższym poziomie abstrakcji nie wpływają na operacje na wyższym poziomie abstrakcji.
Model relacyjny - model organizacji danych bazujący na matematycznej teorii mnogości zbiorów, w szczególności na pojęciu relacji (Relation Database).
W modelu relacyjnym dane grupowane są w relacje, które reprezentowane są przez tablice. Relacje są pewnym zbiorem rekordów o identycznej strukturze. Relacje są zgrupowane w tzw. schematy baz danych. Model relacyjny w porównaniu do innych modeli danych ułatwia wprowadzanie zmian, zmniejsza możliwość pomyłek, ale dzieje się to kosztem wydajności.
Historia
Twórcą teorii relacyjnych baz danych jest Edgar Frank Codd. Postulaty te zostały opublikowane po raz pierwszy w 1970 r. - A Relational Model of Data for Large Shared Data Banks. W 1972 r. w w/w pracy Codd uszeregował opis modelu oraz przedstawił dwa modele formularza odpytywania (przeszukiwania) danych. Tu właśnie po raz pierwszy pojawiły się terminy algebra oraz rachunek relacji.
W roku 1979 firma Relation Software, później Oracle, wypuściła na rynek pierwszy komercyjny szbd.
Edgar Frank "Ted" Codd (ur. 23 sierpnia 1923 w Portland w Anglii, zm. 18 kwietnia 2005) - brytyjski informatyk, znany przede wszystkim ze swojego wkładu do rozwoju teorii relacyjnych baz danych. W 1948 r. przeniósł się do Nowego Jorku, gdzie podjął pracę dla IBM jako programista.
IBM zwlekał z praktycznym zastosowaniem.
W modelu relacyjnym baz danych jednym z kluczowych problemów było podejście do brakujących danych, np. jeśli w polu telefon brak jest danych, to oznacza, że ktoś nie ma telefonu lub my nie znamy jego numeru telefonu. Trwało wiele dyskusji na temat tego, jak to rozwiązać, ale ostatecznie w 1979 r. Codd wprowadził do modelu relacyjnego specjalną wartość NULL. Wprowadzenie tej wartości wiązało się z rozszerzeniem logiki dwuwartościowej do logiki trójwartościowej. Na każde pytanie można teraz odpowiedzieć - NIE lub NIEWIADOMO lub TAK.
Obecnie funkcjonuje wiele spojrzeń na model relacyjny. Dwa główne podejścia to:
- podejście formalne - opisujące model relacyjny poprzez wzory matematyczne, oparte na teorii zbiorów.
- podejście intuicyjne - spojrzenie na model od strony czysto użytkowej
Podejście formalne
Cały model relacyjny jest oparty na matematycznym pojęciu relacji. W ujęciu tym relacją nazywamy dowolny podzbiór iloczynu kartezjańskiego pewnych zbiorów:
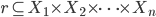
W podejściu formalnym schematem R relacji nazywamy niepusty zbiór nazw atrybutów (w skrócie atrybutów) R = {A1, A2,..., An}. Każdemu atrybutowi Ai przypisany jest zbiór wartości Dom(A) zwany dziedziną (domeną, typem danych) atrybutu A. Jest to nazwany i skończony zbiór wartości, jakie może przyjmować dany atrybut. Wartość n określana jest mianem stopnia relacji R bądź arnością relacji R.
Instancją schematu relacji R to relacja na zbiorze dziedzin atrybutów Ai:
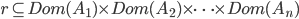
Ponieważ każda relacja r jest nierozłącznie związana ze swoim schematem relacji R, często można spotkać oznaczenie r(R) czytane jako „relacja r typu R”. Może istnieć wiele relacji przyporządkowanych do danego schematu.
Podejście intuicyjne
W modelu relacyjnym, każda relacja (prezentowana np. w postaci tabeli) posiada swoją nazwę, nagłówek i zawartość. Nagłówek to zbiór atrybutów, gdzie atrybut jest parą nazwa atrybutu:nazwa typu, zawartość natomiast jest zbiorem krotek reprezentowanych najczęściej w postaci wiersza w tabeli. Każda krotka wyznacza zależność pomiędzy danymi w poszczególnych komórkach (np. osoba o danym numerze PESEL posiada podane nazwisko, imię oraz adres).

Dane w polu są jednostkowe, atomowe (jednorodne). W każdej tabeli znajduje się klucz podstawowy (główny) od którego zależą pozostałe dane zawarte w krotce.
Z modelem relacyjnym baz danych jest związany język programowania czwartej generacji - SQL - służący do przeszukiwania danych i manipulacji nimi.