1. Klasyfikacja baz danych ze względu na przeznaczenie i sposób zarządznia
- operacyjne bazy danych - są związane z bieżącą działalnością firmy, np. baza produktów połączona z systemem kas fiskalnych w hipermarkecie czy system obsługi klientów w banku czy baza danych do obsługi izby przyjęć w szpitalu.
Bazy operacyjne są optymalizowane pod względem szybkości działania. Charakterystyczną cechą operacyjnych baz danych jest bardzo duża ilość szybko zmieniających się danych. - analityczne (temporarne) bazy danych - służą do przeprowadzania analiz, badania trendów, wyciągania wniosków, podejmowania decyzji strategicznych krótko- i długoterminowych na podstawie danych zebranych w długim okresie czasu w bazach operacyjnych. Przykładem analitycznej bazy danych są hurtownie danych.
2. Klasyfikacja baz danych ze względu na model danych
Model danych to zintegrowany zbiór zasad opisujących dane, relacje, powiązania pomiędzy danymi, dozwolone operacje i ograniczenia nakładane na dane. Model danych można opisać jako konstrukcję składającą się z trzech komponentów:
- części strukturalnej modelu danych, składającej się z reguł określających budowę bazy danych
- części manipulacyjnej określającej, które operacje aktualizacji, pobierania i zmiany struktury można wykonywać na danych zawartych w bazie danych
- część zawierająca reguły integralności, gwarantującej stabilność działania systemu
- bazy jednorodne (kartotekowe) - proste bazy danych oparte na jednej tabeli
- hierarchiczne bazy danych (znaczenie historyczne, obecnie niewykorzystywane, lata 60. XX w.) - w tym modelu przechowywane dane są zorganizowane w postaci drzewa podobnego do struktury plików i folderów na dysku. Informacja zawarta jest w dokumentach oraz w strukturze drzewa.
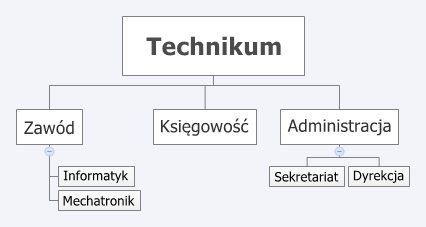 Każdy rekord, z wyjątkiem głównego, który jest na szczycie, jest powiązany z jednym rekordem nadrzędnym.
Każdy rekord, z wyjątkiem głównego, który jest na szczycie, jest powiązany z jednym rekordem nadrzędnym.
Hierarchiczny model baz danych przypomina strukturę odwróconego drzewa posiadającego jeden korzeń, czyli tabelę nadrzędną, oraz "synów" (tabele podrzędne) - jeden ojciec może mieć wiele dzieci, ale dziecko może mieć tylko jednego ojca.
Model hierarchiczny opiera się na dwóch strukturach danych, typach rekordów i związkach nadrzędny-podrzędny. Model ten różni się od relacyjnego, ponieważ związki pomiędzy rekordami określane są nie przez klucz główny czy obcy, lecz związki nadrzędny-podrzędny. W modelu tym nie można wstawić rekordu podrzędnego dopóty, dopóki nie zostanie on powiązany z rekordem nadrzędnym. - sieciowe bazy danych - w modelu tym połączenia między dokumentami tworzą sieć. Informacja jest zawarta w dokumentach oraz w przebiegu połączeń sieci.
Model został opracowany w 1969 roku i obecnie ma znaczenie historyczne.
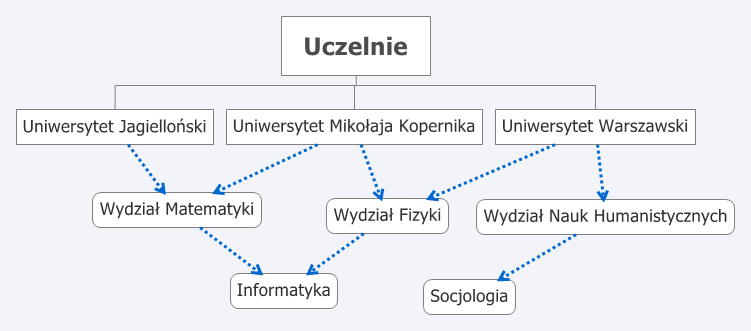


Sieciowy model baz danych definiuje relacje pomiędzy tabelami za pomocą kolekcji. Kolekcja to struktura, dzięki której można połączyć dwie tabele, nadając jednej z nich rolę właściciela (tabeli nadrzędnej), a drugiej - członka kolekcji (tabeli podrzędnej). Kolekcje umożliwiają wprowadzenie relacji jeden-do-wielu, co znaczy, że rekord z tabeli właściciel może być powiązany z wieloma rekordami tabeli podrzędnej, lecz rekord z tabeli podrzędnej może być powiązany tylko z jednym rekordem z tabeli nadrzędnej. Każda tabela może uczestniczyć w wielu różnych kolekcjach, a między każdymi dwoma tabelami można stworzyć dowolną liczbę powiązań.
W sieciowym modelu baz danych dostęp do interesujących nas danych można uzyskać poruszając się po kolekcjach i w przeciwieństwie do hierarchicznego modelu baz danych, przeszukiwanie możemy zacząć od dowolnej tabeli, a następnie poruszać się w górę lub w dół po tabelach z nią powiązanych.
Sieciowy model danych przypomina strukturę odwróconego drzewa, którego gałęzie mogą należeć równocześnie (być wspólne) z innymi drzewami. W praktyce ten model nie miał większego znaczenia, ale na jego podstawie opracowano model relacyjny. - relacyjne bazy danych - oparte są na teorii relacji zbiorów. Zostały opracowane w latach 80. XX w. Obecnie jest powszechnie wykorzystywanym modelem (ok. 70%, patrz: ćwiczenia i kolejne lekcje)
- obiektowe bazy danych - ze względu na ograniczenia relacyjnego modelu danych, w którym struktury danych są płaskie, opracowano model obiektowy, który opiera się na koncepcji obiektów. Podobnie jak w obiektowych językach programowania, obiekt jest odwzorowaniem rzeczywistości lub abstrakcji.
Obiektowe bazy danych korzystają z obiektowego języka zapytać OQL (ang. Object Query Language). Każdy obiekt ma zaprojektowany interfejs określający metody dostępu do tego interfejsu.
Model ten nie jest wykorzystywany powszechnie ze względu na trudną implementację i niezadowalającą wydajność. - obiektowo-relacyjne bazy danych - model relacyjno-obiektowy jest mieszanym modelem bazy danych, częściej używany niż obiektowy. Model ten pozwala w relacyjnych tabelach tworzyć kolumny, w których przechowywane są dane typu obiektowego, co pozwala na definiowanie zmiennych oraz metod, które będą wykonywane na danych wprowadzanych do obiektu.
- model semistrukturalny baz danych (postrelacyjny) - są to relacyjne bazy danych poszerzone o elementy obiektowości i obsługę XML
3. Klasyfikacja baz danych ze względu na liczbę węzłów baz danych
- scentralizowane bazy danych - baza danych znajduje się na jednym serwerze baz danych
- rozproszone bazy danych - baza danych jest rozproszona na wielu serwerach baz danych (np. system DNS)
4. Inne rodzaje baz danych
- temporalne bazy danych - jest odmianą relacyjnej bazy danych, w której każdy rekord posiada stempel czasowy określający czas, w jakim wartość jest prawdziwa. Posiada także operatory algebry relacyjnej, która pozwala operować na danych temporalnych (wyciągać historię).
- bazy danych z informacją geograficzną (GIS) - są to odpowiednio zorganizowane bazy danych o obiektach i zjawiskach, które znajdują się pod ziemią, na jej powierzchni i nad ziemią oraz oprogramowanie, które umożliwia prowadzenie wszelkich złożonych analiz informacji charakteryzujących te obiekty i zjawiska i prezentowanie wyników tych analiz w postaci map, np. geoportal, Mapy Google.
- hurtownia baz danych - jest rozbudowaną bazą danych przechowującą olbrzymią ilość danych zbieranych w długim czasie, pojawiających się w bazach operacyjnych. Przechowywane dane są tematycznie spójne oraz zintegrowane. Operacje przeprowadzane na danych znajdujących się w hurtowniach baz danych mają charakter analityczny. Specyfiką pracy hurtowni danych nie jest efektywne wyszukiwanie pojedynczego rekordu, lecz obliczenia przetwarzania danych na bardzo dużej ilości rekordów lub wszystkich rekordach zawartych w bazie danych.
- systemy ekspertowe (doradcze) - programy oparte na sztucznej inteligencji, które dzięki zgromadzonej bazie wiedzy opierają się na mechanizmach automatycznego wnioskowania. Służą do udzielania komputerowych porad i opinii. Przykładami systemów ekspertowych są: Mycin (służy do badania interakcji antybiotyków z innymi lekami), Dendral (podstawowym zadaniem tego systemu jest ustalenie struktury molekularnej nieznanych chemicznych związków organicznych na podstawie widm analizy spektroskopowej), Prospector (wykorzystywany do wspomagania pracy geologów).
Super strona polecam i pozdrawiam