Replikacja bazy danych polega na powielaniu bazy danych między różnymi serwerami baz danych, co ma miejsce np. przy pracy w klastrze.Replikacja pozwala na:
- skalowalność: dzięki temu możliwe jest rozłożenie obciążenia między wieloma serwerami; operacje zapisu i aktualizacji rekordów mogą odbywać się na jednym serwerze, a pobieranie i przeszukiwanie danych na innych, a znacznie obciążające serwer operacje - na jeszcze innych. Na jednej z kopii mogą pracować analitycy, deweloperzy itp.
- bezpieczeństwo: dzięki replikacji tworzymy kopie istniejącej bazy produkcyjnej, które co prawna nie uchronią nas przed operacjami typu
DROP, ale zapewnią ciągły dostęp do bazy danych w przypadku awarii sprzętu głównego serwera. - analizę: skomplikowane operacje analityczne, różnego rodzaju przeliczenia i analizy statystyczne mogą być wykonywane na osobnym serwerze bez obciążania głównej bazy.
- separację: możemy udostępnić kopię bazy produkcyjnej dla deweloperów i testerów, aby swoje prace wykonywali na kopii bazy danych.
Replikację można podzielić na:
- replikację typu
master-slave- wtedy na bazie produkcyjnej (master) wykonywane są operacje modyfikacji danych, natomiast na pozostałe przenoszona jest kopia bazy danych z serwera głównego - replikację typu
master-master, inaczejduplikacja, gdzie zmiany czy modyfikacje danych mogą być wykonane na dowolnym komputerze i dochodzi do obustronnej synchronizacji baz danych; dzięki takiemu rozwiązaniu zmiany przeprowadzone na jednej z baz danych zostaną również prowadzone na pozostałych.
Aby można było przeprowadzić replikację baz danych, użytkownik, który chce ją przeprowadzić, musi mieć uprawnienia REPLICATION CLIENT i REPLICATION SLAVE, będące uprawnieniami globalnymi.
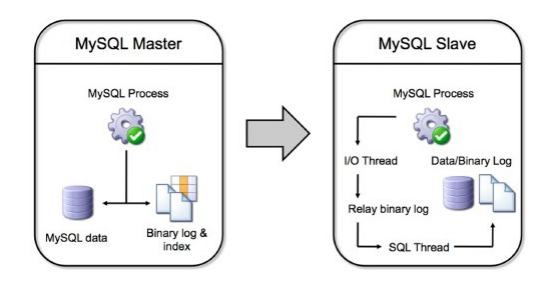
Mechanizmy replikacji master-slave w SZBD MySQL
Replikacja danych w MySQLopiera się o bardzo prostą zasadę: serwer główny (master) prowadzi swego rodzaju dziennik, w którym zapisuje każdą czynność, którą wykonał. Wykorzystuje do tego logi binarne zawierające instrukcje, które wykonał master. Serwer zapasowy (slave) odczytuje te dane i kolejno wykonuje zapytania, zapełniając bazę kolejnymi rekordami. Efektem tej pracy są dwie identyczne bazy danych.
Po skonfigurowaniu mechanizmu replikacji na serwerze master pojawia się dodatkowy wątek, który odpowiada za wysyłanie bin-logów do serwerów slave. Z kolei serwer zapasowy ma dwa wątki:
- I/O Thread [wątek wejścia-wyjścia] - odpowiada za odbieranie dziennika od serwera głównego i zapisuje go w plikach tymczasowych (relay-log),
- SQL Thread [wątek SQL] - zajmuje się parsowaniem tych plików i wykonywaniem zapytań do bazy.
Całą sytuację przedstawia poniższy schemat:
System bazodanowy MySQL umożliwia trzy różne metody replikacji, co przekłada się na format danych zapisywanych do logów binarnych. Za wybór metody replikacji odpowiada zmienna binlog_format, któa może przyjąć wartość: ROW, STATEMENT, MIXED.
Metody replikacji:
- SBR [Statement-Based Replication, replikacja bazująca na zapytaniach] - serwer do pliku zapisuje polecenia, które wykonał,
- RBR [Row-Based Replication, replikacja bazująca na wierszach] - do bin-logów zapisywane są wyniki działań zapytań na serwerze
MASTER. Zapisywana jest informacja, jaki rekord w jaki sposób został zmieniony, - MFL [Mixed-Format Replication, replikacja typu mieszanego] - połączenie dwóch powyższych replikacji.
Technika SBR jest bardzo wydajna i szybka, ponieważ w jej przypadku serwer główny zapisuje do pliku zapytanie, jakie wykonał, następnie serwer zapasowy je odczytuje i wykonuje. Niestety do plików zapisywane są tylko zapytania SQL, co może przyspożyć kłopotów, gdy zapytania będą bardziej złożone.
Problem ten rozwiązała metoda RBR, która do bin-logów zapisuje wyłącznie zmiany, które zaszły po wykonaniu polecenia: zapisywane są informacje na temat sposobu modyfikacji konkretnych rekordów. Niestety ta metoda jest znacznie wolniejsza od poprzedniej oraz zwiększa ilość wysyłanych danych pomiędzy replikującymi się serwerami.
Z pomocą przyszła metoda MFL, w której w większości przypadków logowane są zapytania SQL, tak jak w przypadku metody SBR, natomiast dla zapytań, których wynik nie jest przewidywalny włączana jest replikacja RBR.
Inne serwery bazodanowe używają także replikacji migawkowej - rozprowadzane dane mają stan z pewnego, określonego momentu w czasie. Ten rodzaj replikacji znajduje głównie zastosowanie przy danych, które nie są często modyfikowane, jednak modyfikacje te mogą być znaczne. Zmiany pomiędzy kolejnymi wykonywanymi migawkami nie są monitorowane.